개발을 하다 보면 “공통코드”라는 단어를 자주 듣게 됩니다. “이 기능은 여러 곳에서 쓰이니까 공통코드로 빼자!”라는 말은 개발자라면 한 번쯤 들어봤을 겁니다.
얼핏 들으면 공통코드는 코드 재사용성을 높이고, 중복을 줄이며, 유지보수를 쉽게 만들어줄 것 같은 느낌을 줍니다. 하지만, 공통코드가 항상 좋은 선택은 아닙니다. 오히려 잘못된 공통코드는 프로젝트를 복잡하게 만들고, 객체 지향 설계 원칙을 위배하며, 유지보수성을 떨어뜨리는 주범이 될 수 있습니다.
공통코드와 객체 지향 설계의 충돌
객체 지향 설계에서 중요한 원칙 중 하나는 응집도(cohesion)와 결합도(coupling)의 균형입니다. 응집도는 모듈 내부의 요소들이 얼마나 밀접하게 관련되어 있는지를 나타내며, 결합도는 모듈 간의 의존성을 의미합니다.
응집도를 높이면 모듈 간 결합도가 완화되는 경향이 있습니다. 각 모듈이 자신의 책임에 집중하고 독립적으로 동작할 수 있기 때문에, 다른 모듈과의 불필요한 의존성을 줄일 수 있습니다. 반면, 공통코드를 남용하면 모듈 간 의존성이 증가하고, 변경에 취약한 구조가 되어 유지보수성과 확장성이 저하될 수 있습니다. 따라서, 응집도를 높이고 결합도를 줄이는 방향으로 설계하며, 공통코드는 신중하게 사용해야 합니다.
1. 책임의 분산
공통코드는 여러 곳에서 재사용되기 위해 만들어지다 보니, 특정 객체의 책임을 벗어나게 되는 경우가 많습니다. 예를 들어, A 모듈과 B 모듈에서 공통으로 사용하는 기능을 묶어 공통코드로 만들었다고 가정해봅시다. 그런데 시간이 지나면서 C 모듈에서도 이 코드를 사용하고 싶어지고, 결국 공통코드는 A, B, C 모듈의 요구사항을 모두 만족시키기 위해 점점 복잡해집니다. 이렇게 되면 공통코드는 특정 책임을 가지지 못하고, 여러 모듈의 요구사항을 억지로 떠안는 “만능 코드”가 되어버립니다.
2. 교집합이 아닌 합집합으로 만들어지는 공통코드
공통코드를 만들 때 가장 흔히 저지르는 실수 중 하나는, 교집합이 아닌 합집합으로 공통코드를 만드는 것입니다.
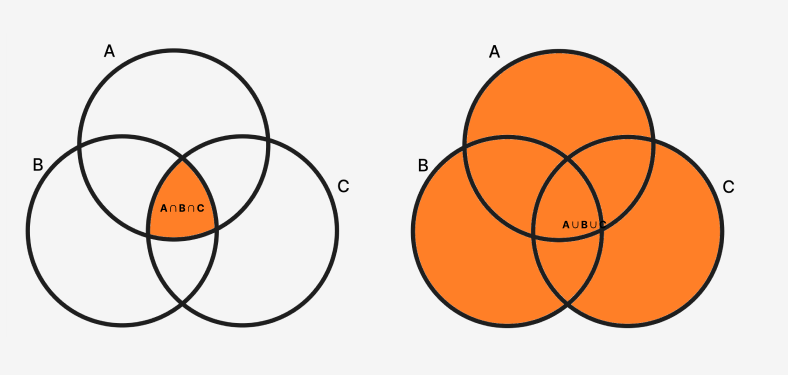
예를 들어, A 모듈, B 모듈, 그리고 C 모듈에서 비슷한 기능을 발견했다고 가정해봅시다. 이 세 모듈의 공통된 부분(교집합)만 추출해서 공통코드를 만들어야 하는데, 많은 경우 A, B, C의 모든 요구사항(합집합)을 만족시키는 코드를 작성하게 됩니다. 이렇게 되면 공통코드는 점점 복잡해지고, 특정 모듈에 불필요한 기능까지 포함하게 됩니다. 결국, 공통코드는 “모든 것을 처리할 수 있는 만능 코드”가 되어버리고, 이는 다음과 같은 문제를 초래합니다:
- 불필요한 의존성 증가:
A 모듈에는 필요 없는 기능이 공통코드에 포함되어 있어도, A는 이를 의존하게 됩니다. 마찬가지로 B와 C도 자신들에게 필요 없는 기능을 포함한 공통코드에 의존하게 됩니다. - 유지보수의 어려움:
공통코드가 복잡해질수록, 특정 모듈(A, B, 또는 C)의 요구사항을 수정하려면 다른 모듈에 영향을 미치지 않도록 신경 써야 합니다. - 가독성 저하:
공통코드가 A, B, C의 합집합으로 개발하게 되면 코드를 이해하기 어려워집니다.
이처럼 공통코드를 만들 때 모든 모듈의 요구사항을 무조건 만족시키려 하면, 코드의 복잡도가 증가하고 유지보수가 어려워질 수 있습니다. 따라서 공통코드는 진정으로 공통된 부분만 추출하고, 각 모듈의 특수한 요구사항은 개별적으로 처리하는 것이 중요합니다
공통코드의 단점과 위험성
공통코드는 처음에는 “효율적”으로 보일 수 있지만, 시간이 지날수록 프로젝트에 악영향을 미칠 가능성이 큽니다. 그 이유를 하나씩 살펴보겠습니다.
1. 변경의 어려움
공통코드는 여러 곳에서 사용되기 때문에, 하나의 변경이 여러 모듈에 영향을 미칠 수 있습니다. 예를 들어, 공통코드의 작은 수정이 예상치 못한 곳에서 버그를 유발할 수 있고 개발 단계에서 이러한 사이드 이펙트들을 발견하기 어렵습니다. 이런 상황이 반복되면 개발자들은 공통코드 수정에 두려움을 느끼게 되고, 결국 공통코드는 “건드리면 안 되는 코드”로 전락하게 됩니다.
2. 테스트의 복잡성 증가
공통코드는 여러 모듈에서 사용되기 때문에, 공통코드를 수정할 때마다 이 코드가 사용되는 모든 모듈을 테스트해야 합니다. 이는 테스트의 복잡성을 크게 증가시키고, 개발 속도를 저하시킵니다.
3. 재사용의 함정
공통코드는 “재사용”을 목적으로 만들어지지만, 실제로는 재사용이 어려운 경우가 많습니다. 이유는 간단합니다. 공통코드는 여러 요구사항을 만족시키기 위해 점점 복잡해지고, 특정 상황에 맞게 수정하기 어려운 코드가 되기 때문입니다. 결국 공통코드를 사용하는 대신, 각 모듈에서 비슷한 코드를 새로 작성하는 일이 발생하게 됩니다.
공통코드는 발견하는 것이다
공통코드를 작성할 때 흔히 저지르는 또 다른 실수는, 공통코드를 억지로 만들어내는 것입니다.
저는 공통코드가 뉴턴이 이미 존재하던 자연 현상을 관찰하고 발견해서 이를 정리해 법칙으로 만든 것처럼 내가 작성한 코드에서 공통된 목적과 공통의 기능을 발견하고 이를 정리하는 것이라고 생각합니다.
하지만 아직 명확히 드러나지 않은 공통점을 억지로 찾아내려 하거나, 단순히 코드의 중복을 줄이겠다는 이유만으로 공통코드를 만들어 낸다면 다음과 같은 문제를 초래할 수 있습니다:
- 미성숙한 공통코드: 충분히 검증되지 않은 공통점을 기반으로 작성된 코드는, 시간이 지나면서 점점 더 많은 수정과 보완이 필요해집니다.
- 불필요한 복잡성: 공통점이 명확하지 않은 상태에서 코드를 묶으려다 보면, 오히려 코드가 복잡해지고 이해하기 어려워집니다.
- 유지보수의 어려움: 억지로 만들어진 공통코드는 실제로는 공통된 목적을 가지지 않는 경우가 많아, 수정할 때마다 여러 모듈에 영향을 미치게 됩니다.
따라서 공통코드는 억지로 만들어내는 것이 아니라, 코드가 충분히 작성되고, 공통된 목적과 기능이 명확히 드러났을 때 발견하고 정리하는 것이어야 합니다.
왜 공통코드를 고집하지 않아야 할까?
그렇다면, 공통코드를 고집하지 않는 것이 왜 중요할까요?
1. 중복은 항상 나쁜 것이 아니다
많은 개발자들이 “중복은 나쁘다”는 생각에 사로잡혀 있습니다. 하지만 모든 중복이 나쁜 것은 아닙니다. 때로는 비슷한 코드가 여러 곳에 존재하더라도, 각 코드가 해당 모듈의 책임과 역할에 맞게 작성되어 있다면, 이는 문제가 되지 않습니다. 오히려 이런 방식이 코드의 가독성과 유지보수성을 높이는 경우가 많습니다.
2. 변경에 유연한 설계
공통코드를 만들지 않고, 각 모듈이 자신의 책임에 맞는 코드를 가지도록 설계하면, 변경이 필요한 경우에도 해당 모듈만 수정하면 됩니다. 이는 변경의 영향을 최소화하고, 시스템의 안정성을 높이는 데 기여합니다.
3. 객체 지향 설계 원칙 준수
공통코드를 고집하지 않으면, 객체 지향 설계 원칙을 더 잘 준수할 수 있습니다. 각 객체가 자신의 책임과 역할을 명확히 가지게 되고, 캡슐화와 응집도를 유지할 수 있습니다.
결론: 공통코드는 신중하게 사용하자
공통코드는 잘 사용하면 코드 재사용성을 높이고, 중복을 줄이는 데 기여할 수 있습니다. 하지만 무분별한 공통코드의 사용은 객체 지향 설계를 위배하고, 유지보수성을 떨어뜨리며, 프로젝트를 복잡하게 만들 수 있습니다.
공통코드를 만들기 전에 다음과 같은 질문을 고려해 봐야 합니다.
- 이 코드는 정말로 여러 곳에서 재사용될 필요가 있는가?
- 공통코드로 만들었을 때, 변경이 어려워지거나 테스트가 복잡해지지는 않을까?
- 이 코드는 특정 모듈의 책임을 침범하지 않는가?
- 공통코드가 교집합만 포함하고 있는가, 아니면 합집합으로 만들어져 불필요한 기능까지 포함하고 있는가?
- 이 공통코드는 억지로 만들어낸 것이 아니라, 충분히 작성된 코드에서 발견된 공통된 목적과 기능을 정리한 것인가?
공통코드는 “필요할 때”만, 그리고 “신중하게” 사용하는 것이 중요합니다. 때로는 중복을 허용하고, 각 모듈이 자신의 책임에 맞는 코드를 가지도록 설계하는 것이 더 나은 선택일 수 있습니다.